取代或轉(zhuǎn)型?人工智能對軟件測試的深度影響與工具革新
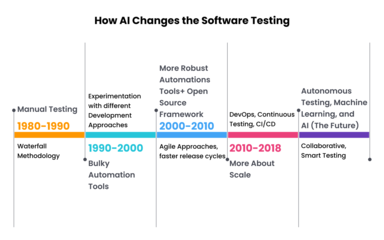
在人工智能(AI)浪潮席卷全球的背景下,軟件測試領(lǐng)域正站在一個關(guān)鍵的十字路口。傳統(tǒng)的手工測試和部分自動化測試,是否會被AI完全取代?還是測試工程師將借此契機,完成一次深刻的職業(yè)轉(zhuǎn)型?本文將深入探討AI對軟件測試的影響,并聚焦于AI應(yīng)用軟件開發(fā)的測試環(huán)節(jié),推薦一系列前沿工具,為從業(yè)者提供清晰的導(dǎo)航。
一、 人工智能:測試領(lǐng)域的顛覆者與賦能者
AI并非簡單地“取代”測試人員,而是在重新定義測試的價值與邊界。其核心影響體現(xiàn)在以下幾個方面:
- 效率的指數(shù)級提升:AI驅(qū)動的測試工具能夠自動生成海量測試用例、執(zhí)行回歸測試、并分析結(jié)果。尤其在UI測試和API測試中,AI可以通過學(xué)習(xí)用戶行為模式和接口規(guī)范,實現(xiàn)更智能、更快速的覆蓋,將測試人員從重復(fù)性勞動中解放出來。
- 測試深度與廣度的突破:傳統(tǒng)測試受限于人力和預(yù)設(shè)場景。AI,特別是機器學(xué)習(xí)(ML)模型,能夠通過分析歷史缺陷數(shù)據(jù)、代碼變更和用戶日志,預(yù)測潛在的缺陷高發(fā)區(qū)域,并探索出人類測試員難以想到的“邊緣場景”和異常路徑,大大提升了測試的覆蓋率和發(fā)現(xiàn)深層缺陷的能力。
- 智能分析與決策支持:AI可以實時分析測試執(zhí)行過程中產(chǎn)生的日志、性能數(shù)據(jù)和屏幕截圖。當(dāng)測試失敗時,AI能快速定位根因,甚至提出修復(fù)建議。它還能根據(jù)風(fēng)險模型,動態(tài)調(diào)整測試優(yōu)先級,實現(xiàn)“智能測試調(diào)度”。
- 對AI應(yīng)用軟件測試的特殊挑戰(zhàn)與機遇:當(dāng)被測對象本身就是AI應(yīng)用(如基于機器學(xué)習(xí)的推薦系統(tǒng)、計算機視覺應(yīng)用、自然語言處理工具)時,傳統(tǒng)基于確定性的測試方法面臨挑戰(zhàn)。測試AI應(yīng)用需要驗證其模型準(zhǔn)確性、偏見、魯棒性以及在未見數(shù)據(jù)上的表現(xiàn)。這催生了“AI測試AI”的新范式,即使用AI工具來測試AI軟件的功能、性能和倫理邊界。
二、 測試工程師的轉(zhuǎn)型:從執(zhí)行者到戰(zhàn)略家與質(zhì)量賦能者
面對AI的滲透,測試工程師的角色必須進化:
- 核心價值轉(zhuǎn)移:工作的重點將從“找Bug”轉(zhuǎn)向“設(shè)計如何更好地找Bug的機制”、“定義質(zhì)量評估體系”和“管理測試數(shù)據(jù)與模型”。測試人員需要深入理解AI模型的原理,以便設(shè)計有效的驗證策略。
- 技能升級:掌握基礎(chǔ)的AI/ML知識、數(shù)據(jù)分析技能、編程能力(如Python)以及對測試中臺、CI/CD管道的駕馭能力,變得至關(guān)重要。測試人員需要能夠配置、訓(xùn)練和評估用于測試的AI模型。
- 質(zhì)量倡導(dǎo)者:在DevOps和敏捷環(huán)境中,測試人員更早介入需求與設(shè)計階段,關(guān)注可測試性、數(shù)據(jù)質(zhì)量和AI倫理(如公平性、透明性),成為產(chǎn)品質(zhì)量的全程賦能者。
三、 AI應(yīng)用軟件開發(fā)測試工具推薦
以下工具覆蓋了從通用測試自動化到專項AI模型測試的多個層面,助力應(yīng)對新時代的測試挑戰(zhàn):
- 功能與UI自動化測試
- Testim:利用AI穩(wěn)定UI測試元素定位,即使UI發(fā)生微小變化也能自動修復(fù)測試腳本,顯著提升測試腳本的健壯性和維護效率。
- Applitools:提供基于AI的視覺測試和監(jiān)控平臺,使用視覺AI來檢測UI中的視覺缺陷、布局問題和跨設(shè)備/瀏覽器的渲染差異,遠超像素對比。
- 測試用例智能生成與管理
- Functionize:通過自然語言處理(NLP),允許用 plain English 創(chuàng)建測試,并利用AI引擎自動生成和執(zhí)行復(fù)雜的測試用例,無需編寫代碼。
- ReTest:專注于基于需求的AI測試生成,能根據(jù)需求描述自動創(chuàng)建測試用例,并管理需求與測試之間的可追溯性。
- API與性能測試智能分析
- LoadRunner Cloud / NeoLoad(Micro Focus & Tricentis):集成AI分析功能,能在性能測試執(zhí)行中自動識別性能瓶頸、異常模式,并提供優(yōu)化建議。
- Postman(未來趨勢):雖然目前主要是一個API協(xié)作平臺,但其正在積極探索集成AI來幫助生成API測試、分析響應(yīng)模式和預(yù)測API行為。
- 專為AI/ML模型測試與監(jiān)控設(shè)計
- Kolena:專用于ML模型測試的平臺。允許團隊系統(tǒng)性地定義測試用例(基于數(shù)據(jù)切片,如特定人群、場景),自動化評估模型的準(zhǔn)確性、穩(wěn)健性、公平性和偏差,確保模型質(zhì)量。
- Fiddler AI:提供AI可觀察性平臺,專注于監(jiān)控生產(chǎn)環(huán)境中ML模型的表現(xiàn)、解釋模型預(yù)測、檢測數(shù)據(jù)漂移和模型性能衰減,是AI應(yīng)用上線后質(zhì)量保障的關(guān)鍵工具。
- Great Expectations:一個開源的數(shù)據(jù)質(zhì)量測試框架。在AI項目中,高質(zhì)量的訓(xùn)練數(shù)據(jù)和輸入數(shù)據(jù)至關(guān)重要。此工具可以幫助測試人員和數(shù)據(jù)工程師定義、自動化執(zhí)行和記錄對數(shù)據(jù)的“期望”(斷言),確保數(shù)據(jù)的有效性、一致性和完整性。
###
人工智能不會讓軟件測試消失,而是讓“低價值”的重復(fù)勞動消失。它迫使測試行業(yè)向更智能、更戰(zhàn)略性的方向發(fā)展。對于AI應(yīng)用軟件開發(fā)而言,測試的復(fù)雜性和重要性不降反升。未來的成功測試團隊,必然是善于利用AI工具增強自身能力,同時將人類獨有的批判性思維、業(yè)務(wù)洞察和倫理判斷深度融入質(zhì)量流程的團隊。轉(zhuǎn)型,而非取代,是這場變革的主旋律。 擁抱變化,升級技能,方能在AI時代繼續(xù)守護軟件質(zhì)量的基石。
最新產(chǎn)品

通用股份獲評國家級工業(yè)設(shè)計中心,人工智能應(yīng)用軟件開發(fā)引領(lǐng)行業(yè)創(chuàng)新

軟件測試成為軟件開發(fā)關(guān)鍵環(huán)節(jié),Testin云測引領(lǐng)AI應(yīng)用開發(fā)新浪潮
矽遞科技發(fā)布首款實用級RISC-V架構(gòu)Linux電腦,開啟AI應(yīng)用開發(fā)新紀(jì)元
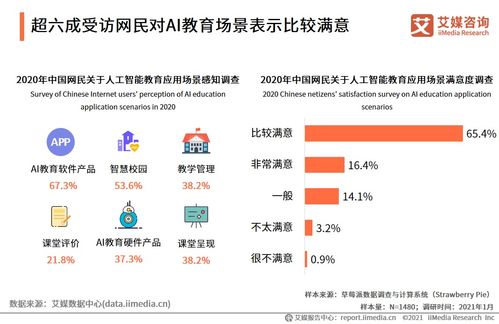
人工智能行業(yè)數(shù)據(jù)分析 2020年中國81.8%網(wǎng)民對AI教育應(yīng)用場景滿意

RF技術(shù)社區(qū)與非網(wǎng)射頻工程師社區(qū) 人工智能應(yīng)用軟件開發(fā)的協(xié)同創(chuàng)新之路
從理論到實踐 人工智能、機器學(xué)習(xí)及其應(yīng)用軟件開發(fā)簡史
取代或轉(zhuǎn)型?人工智能對軟件測試的深度影響與工具革新

剖析人工智能必學(xué)語言——Python的優(yōu)缺點及應(yīng)用范圍
明日之星 深言科技榮獲2024年度中國人工智能行業(yè)高科技高成長企業(yè)殊榮
AI智能人像修圖軟件 Python人工智能在CSDN視角下的應(yīng)用軟件開發(fā)實踐